
To Author's Page
In part 1 of this blog series Deep Learning: becoming a data scientist and fulfilling your creative potential we state that the promise of higher order “congitive intelligence” is out of reach with current algorithms. Regardless of this lack of “human-like” cognitive intelligence, there are a great number of potential applications.
At Frankfurt School, we are for example working on an application that can predict from the cursor flow of customers, whether they are going to buy a particular product. The application also gives an indication on features of the decision process that imply why a particular decision has been made. Furthermore, in the area of Natural Language Generation (NLG), we are developing an algorithm to write marketing emails better than a human being could do.
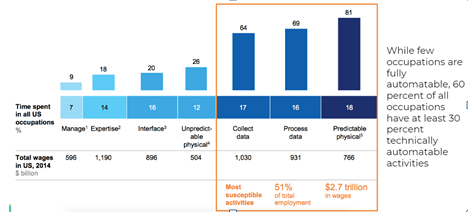
The potential of existing deep learning algorithms to automate different tasks is illustrated in the figure above. While only a few occupations are fully automatable, 60 per cent of all occupations have at least 30 per cent technically automatable activities, implying a great potential for companies. The activities that can be best automated are those where similar tasks are performed repeatedly such as in predictable physical work, data processing or data collection.
Successful use cases require an adaptation of algorithms to the particular company requirements. One of the key questions here is whether to develop solutions in-house or to rely on external providers. It is important not to reinvent the wheel, particularly since there is a large number of pre-existing solutions as well as intermediate, adaptable off the shelve algorithms available.
At the same time, it makes sense for a company to develop applications in-house in areas that are key to its competitive advantage. In those areas, the technology must not be outsourced as the company risks losing its competitive advantage and becoming an exchangeable commodity otherwise. Fortunately, most research in machine learning and the algorithms used are publicly available, implying that a well-trained team of data-scientists can make rapid progress in using these algorithms for the applications relevant for that company.
In doing so companies have to pursue a mixed strategy. On the one hand, hiring external expertise such as a PhD in computer science or specifically machine learning can be extremely useful. On the other hand, data science or closely related fields such as algorithmic optimization is nothing new in most companies and has been performed for many years in R&D, operations and IT departments.
In each case, it is possible to update knowledge of the existing workforce to be able to employ deep learning algorithms. Frankfurt School offers a continuing education programme the Certified Expert in Data Science and Artificial Intelligence. The course covers the theoretical foundations of statistical modelling, the detailed analysis of neural models – along with associated machine learning procedures – and includes a technical introduction to and practice in Python programming using the general “Data Science Stack” (Numpy, SciPy, Pandas, Scikit-Learn), as well as TensorFlow for Deep Learning.
Frankfurt School gGmbH
Adickesallee 32-34
60322 Frankfurt am Main

