

Autorenprofil
Die Anwendung von Künstlicher Intelligenz (KI) im Audit stellt zunehmend eine wertvolle Unterstützung für Prüfer:innen in unterschiedlichsten Prüfungshandlungen dar. So werden z.B. heute bereits KI-Modelle im Rahmen von Jahresabschlussprüfungen für das Audit Sampling[1], Journal Entry Testing[2], oder der Prüfung von Anhangsangaben[3] eingesetzt.
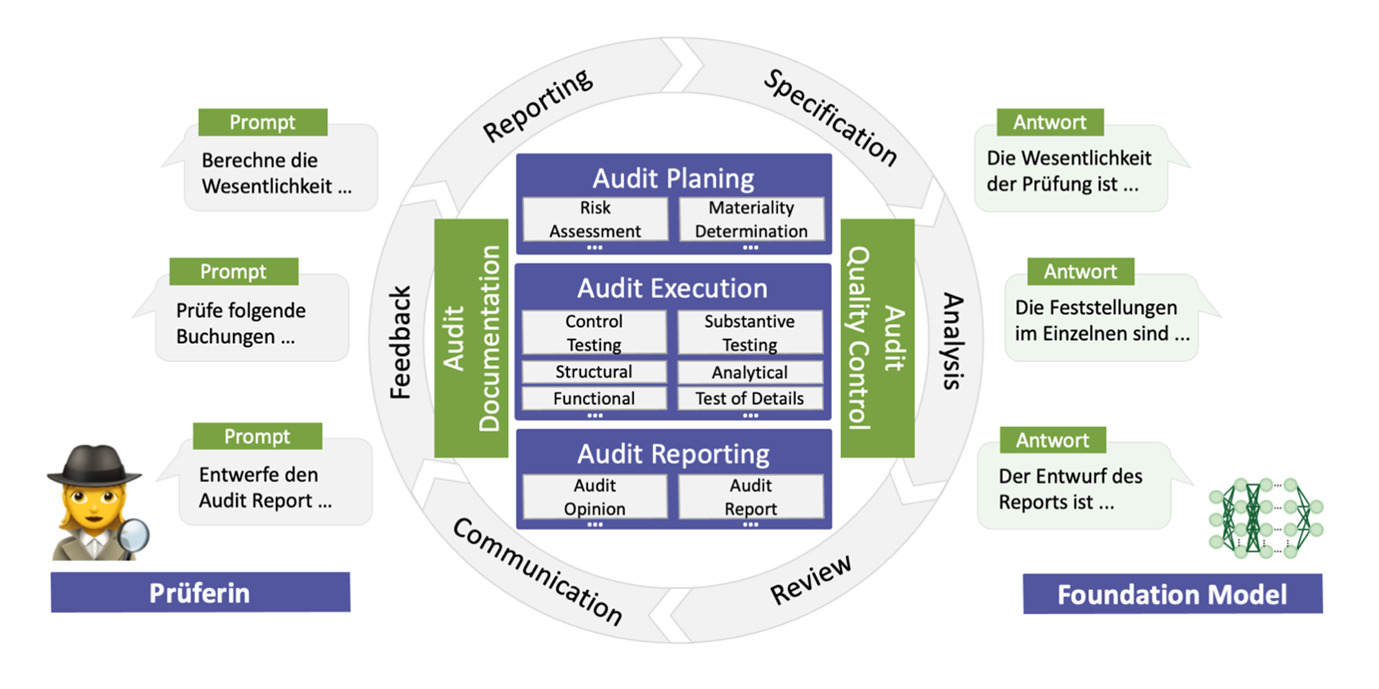 Abbildung 1: Übersicht „Co-Piloted Auditing“ im Kontext des Prüfungsprozesses
Abbildung 1: Übersicht „Co-Piloted Auditing“ im Kontext des Prüfungsprozesses
Die Idee des Co-Piloted Auditing beschreibt im prüferischen Kontext einen Paradigmenwechsel, in welchem Prüfer:innen und KI, anhand sogenannter Foundation Models[4], zusammenarbeiten, um ihre jeweils komplementären Fähigkeiten in den Prozess der Prüfung einzubringen:
Zugleich handelt es sich bei Foundation Modellen, wie z.B. OpenAI’s GPT-4[5] bzw. Google’s LaMDA[6], um KI-Modelle, welche für verschiedenste Aufgaben adaptiert werden können.
Im Allgemeinen durchlaufen diese Modelle ein zweistufiges Trainingsverfahren. In der ersten Phase, dem sogenannten Pre-Training, werden die Modelle anhand umfangreicher Daten trainiert, um allgemeine Muster und Strukturen zu erlernen. In der zweiten Phase, dem sogenannten Fine-Tuning, werden die Modelle mit Daten einer geringen domänen-spezifischen Datenmenge adaptiert, um das Lösen einer konkreten Aufgabenstellung zu erlernen. Dieser zweistufige Prozess ermöglicht das Fine-Tuning eines pre-trainierten Foundation KI-Models für eine Vielzahl unterschiedlicher Aufgabenstellungen, z.B. Programmierung von Software, Analyse von Kundenfeedback, oder der Assistenz in Lernprozessen.
Die durch OpenAI‘s veröffentlichte ChatGPT[7] bzw. die durch Google veröffentlichte Bard[8] Anwendung ermöglichen das Fine-Tuning des jeweils zugrundeliegenden Foundation KI-Models GPT-4 bzw. LaMDA anhand sogenannter Prompts. Solche Prompts bezeichnen Texteingaben, welche es dem Model ermöglichen anhand natürlicher Sprache von den Prüfer:innen zu lernen. Anhand der Abfolge solcher Texteingaben in sogenannten Prompt Protokollen kann das fine-tuning von Foundation KI-Modellen für verschiedene Prüfungsaufgaben erfolgen.
Ein Audit Prompt Protokoll, unterteilt eine prüferische Aufgabe in sukzessiv aufeinander aufbauende Lernschritte. Anhand des Protokolls leiten die menschlichen Prüfer:innen das Fine-Tuning des Foundation KI-Model an. In der prüferischen Praxis hat sich die Einhaltung eines aus fünf Prompts bestehenden Prompt Protokolls bewährt:
Im Anschluss an das erfolgreiche Fine-Tuning ist es dem Foundation Model möglich, eigenständig die erlernte prüferische Aufgabe zu bewerkstelligen. Abbildung 2 zeigt das Ergebnis eines für das Journal Entry Testings[9] fine-getunten GPT-4 Modells. Durch ein entsprechendes Audit Prompt Protokoll wurde dem Foundation Model die Fähigkeit vermittelt ungewöhnliche Buchungen einer Finanzbuchhaltung zu erkennen.
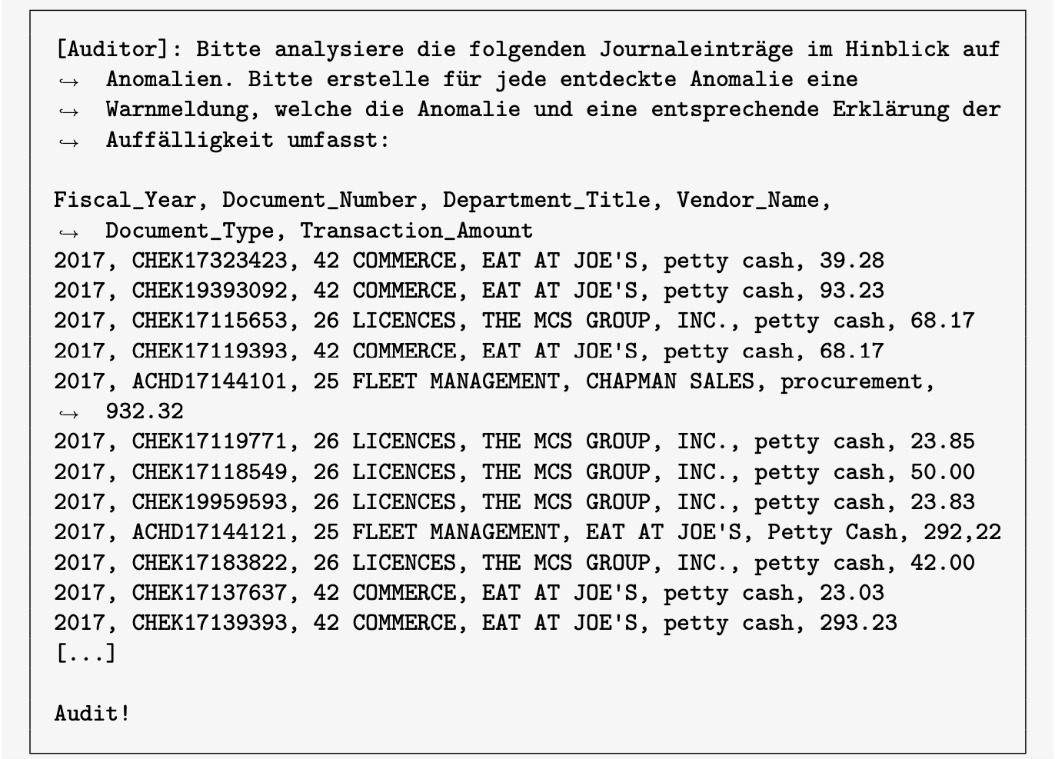

Abbildung 2: Beispielergebnis eines Journal Entry Testing nach ISA 240. Prompt der Prüferin (oben) und Ausgabe des Foundation Model’s (unten)
Anhand des fine-tunens von Foundation KI-Modellen ergeben sich zunehmend neue Möglichkeiten für Prüfer:innen. Aktuell erstreckt sich die Anwendung noch auf vermeintlich grundlegende Aufgaben wie z.B. Wesentlichkeitsbewertung, Transaktionsprüfung und Prüfung von Anhangsangaben. Zukünftig wird das Co-Piloted Auditing Paradigma die Anwendung Künstlicher Intelligenz die Prüfungspraxis zunehmend transformieren.
Der Zertifikatsstudiengang Certified Audit Data Scientist greift diesen technologischen Wandel auf und vermittelt moderne KI-unterstützte Prüfverfahren.
————————————————————————————————————————————————————————————————————————————–
Dieser Blogbeitrag stellt einen Auszug des nachfolgenden, durch den Autor gemeinsam mit Co-Autoren veröffentlichten Beitrags dar: „Artificial Intelligence Co-Piloted Auditing“,
Gu, H., Schreyer, M. and Moffitt, K. and Vasarhelyi, M. A. (online verfügbar).
Marco Schreyer ist Dipl. Wirtschaftsinformatiker und verfügt über mehrjährige Erfahrung der forensischen Datenanalyse in der Prüfungs- und Revisionspraxis. Derzeit erforscht er an der Universität St.Gallen (HSG) die Anwendungsmöglichkeiten von Deep Learning Verfahren in der internen und externen Prüfung. Marco Schreyer ist Dozent der Zertifikatsstudiengänge Certified Audit Data Scientist und Certified Fraud Manager an der Frankfurt School.
————————————————————————————————————————————————————————————————————————————–
[1] Schreyer, M., Gierbl, A.S., Ruud, F. and Borth, D., 2022. Stichprobenauswahl durch die Anwendung von Künstlicher Intelligenz-Lernen repräsentativer Stichproben aus Journalbuchungen in der Prüfungspraxis. Expert Focus, (02), pp.10-18.
[2] Schreyer, M., Baumgartner, M., Ruud, F. and Borth, D., 2022. Künstliche Intelligenz im Internal Audit als Beitrag zur Effektiven Governance-Deep-Learning basierte Detektion von Buchungsanomalien in der Revisionspraxis. Expert Focus, (01), pp.39-44.
[3] Ramamurthy, R., Pielka, M., Stenzel, R., Bauckhage, C., Sifa, R., Khameneh, T.D., Warning, U., Kliem, B. and Loitz, R., 2021, August. Alibert: Improved Automated List Inspection (ALI) with BERT. In Proceedings of the 21st ACM Symposium on Document Engineering (pp. 1-4).
[4] Bommasani, R., Hudson, D.A., Adeli, E., Altman, R., Arora, S., von Arx, S., Bernstein, M.S., Bohg, J., Bosselut, A., Brunskill, E. and Brynjolfsson, E., 2021. On the Opportunities and Risks of Foundation Models. arXiv preprint arXiv:2108.07258.
[5] https://openai.com/research/gpt-4
[6] https://blog.google/technology/ai/lamda/
[7] https://chat.openai.com
[8] https://bard.google.com
[9] Vgl. International Auditing and Assurance Standards Board. 2009. International Standard on Auditing (ISA) 240: The Auditor’s Responsibilities Relating to Fraud in an Audit of Financial Statements. International Federation of Accountants (IFAC).
Frankfurt School gGmbH
Adickesallee 32-34
60322 Frankfurt am Main

