

Autorenprofil
Bei Datenanalysen in den Bereichen Ökonomie und Business spielt das Verständnis, die Selektion und die Aufbereitung der Daten eine entscheidende Rolle, um gute und valide Ergebnisse zu erzielen. Die Notwendigkeit für das Verständnis beginnt dabei nicht erst bei den Daten, sondern bereits bei der zugrundliegenden Problemstellung, auf deren Basis bspw. die Kostenfunktion sowie die Qualitätsmetriken bestimmt werden müssen. Üblicherweise werden für die Phasen Datenselektion und -aufbereitung 70-80% der Projektzeit aufgewendet, was deren Bedeutung dokumentiert.
Auf die Daten werden schließlich Methoden und Algorithmen angewendet, um die Analyse, z.B. in Form der Erstellung eines Prognosemodells, durchzuführen. Für die jeweiligen Anwendungsbereiche steht dazu heutzutage eine Vielzahl an Methoden zur Verfügung, die von einfachen linearen Ansätzen, wie z.B. einer statistische OLS-Regression, über komplexere nichtlineare Ansätze, wie z.B. Random Forest, bis hin zu hochkomplexen Ansätzen, wie z.B. Deep Learning, reichen.
Auch wenn die letztgenannten komplexeren Ansätze in der jüngeren Zeit viele Erfolgsgeschichten verbuchen können, sind sie dennoch nur von Nutzen, wenn sie mit den „richtigen“ Daten gefüttert werden. Im Vergleich dazu leistet die Auswahl des Algorithmus dann oft eher nur einen marginalen Beitrag zum Ergebnis.
Es gilt dabei, dass ein Algorithmus nur das lernen kann, was ihm über die Daten zur Verfügung gestellt wird. Damit bekommt die Selektion der „richtigen“ Daten bezogen auf die spezifische Problemstellung eine entscheidende Bedeutung. Ein Data Scientist muss hier zum einen die Problemstellung verstanden haben und zum anderen in der Lage sein, die dafür passenden Daten auszuwählen und für die Analyse aufzubereiten.
Die für die Analysen benötigten Informationen sind zudem häufig in den Daten verborgen. Die Annahme, dass die Algorithmen diese selbständig finden und extrahieren können, ist illusorisch. Vielmehr bedarf es eines mitunter aufwändigen sog. Feature Engineering, um den Algorithmen die in den Daten steckenden Informationen sichtbar zu machen. Hierbei handelt es sich zum Teil um vergleichsweise simple Vorgänge, wie z.B. die Transformation von Exportvolumina in Exportquoten, um sie zwischen Ländern vergleichbar zu machen. Etliche der Vorgänge sind aber auch komplexer Natur, wie z.B. das Finden von zyklischen Informationen in zeitbezogenen Daten.
Das dafür erforderliche Wissen ist stark vom jeweiligen Anwendungsbereich abhängig und unterscheidet sich nachhaltig z.B. zwischen Ökonomie und Medizin. Daher wird es auch als Domänenwissen (Domain Expertise) bezeichnet und gilt als eine der fundamentalen Fähigkeiten eines Data Scientisten (siehe auch nachfolgende Abbildung).
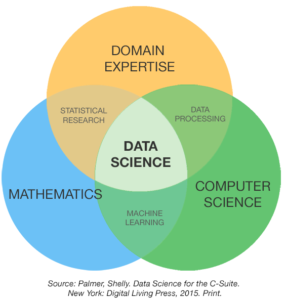
Ist das Wissen nicht in ausreichendem Maße vorhanden, führt dies allzu oft dazu, dass Algorithmen mehr oder weniger blind auf das verfügbare Datenmaterial angewendet werden. Dazu wird dann den Standard-Qualitätsmetriken der verwendeten Softwaretools zur Bewertung der Ergebnisse vertraut, ohne beurteilen zu können, ob sie sich für die Problemstellung eignen oder nicht. Solche Analysen können in der Praxis fatale Folgen haben.
Ich mache derartige Erfahrungen häufig mit Studierenden, die keine ökonomische Vorbildung haben und stattdessen eine Vorbildung bspw. in Mathematik, Physik oder Informatik mitbringen. Typisch in den Case Studies in den Veranstaltungen ist dann das oben geschilderte Vorgehen und der Glaube an gute Ergebnisse aufgrund der verwendeten Algorithmen und Metriken. Selbst auf Nachfrage ist den Studierenden oft nicht bewusst, dass etwas nicht stimmt bzw. was nicht stimmt.
Ein klassischer Case ist eine Credit Scoring Analyse. Das verfügbare Datenmaterial ist in diesem Fall ungleich verteilt, da in der Praxis deutlich mehr Kredite existieren, bei denen der Verlauf positiv war. Dieser Ungleichverteilung muss sowohl bei der Datenaufbereitung als auch in der verwendeten Metrik Rechnung getragen werden, da der Algorithmus das Entscheidungsmodell auf die Erkennung der Klasse „nicht kreditwürdig“ fokussieren soll. Es nutzt einer Bank nichts, wenn sie lediglich die Klasse „kreditwürdig“ zuverlässig erkennt. Genau dies sind aber oft die Ergebnisse, wenn nicht mit dem notwendigen ökonomischen Sachverstand vorgegangen wird.
Besteht das Datenmaterial bspw. zu 90% aus Fällen mit einem positiven Kreditverlauf und nur zu 10% aus denen mit einem negativen, so hätte man hypothetisch eine Trefferhäufigkeit (Accuracy) von 90%, wenn man alle positiven Fälle korrekt über das Modell identifiziert und alle negativen falsch. Und tatsächlich würde sich der Algorithmus auf die Erkennung der größeren Klasse fokussieren, da hier das größere Potential besteht, die Accuracy zu optimieren.
Nun existieren verschiedene Vorgehensweisen, um diese Ungleichverteilung der Klassen zu behandeln. Diese müssen geprüft werden, um die optimale Variante auszuwählen. Auch dabei kann es zu Kombinationen zwischen Vorgehensweise und Metrik kommen, die nicht die gewünschten Ergebnisse bringen. Ein klassischer Fall ist hier die künstliche Herstellung einer Gleichverteilung der Klassen über Up- bzw. Downsampling in Verbindung mit der Accuracy als Metrik. Auch hier bedeuten hohe Trefferquoten nicht, dass die Klasse „nicht kreditwürdig“ ausreichend gut erkannt wird. Dies kann man dann z.B. erst über einer Betrachtung der sog. Confusion Matrix beurteilen, wofür bei fehlendem Domänenwissen aber oft nicht die Notwendigkeit erkannt wird.
Der dargestellte Fall ist noch recht offensichtlich. Dennoch werden diese Fehler immer wieder gemacht, selbst wenn ähnliche Fälle bereits vorher in den Veranstaltungen diskutiert wurden. Das Problem ist, dass bereits die Kostenfunktion nicht verstanden wird. Die Kosten einer Fehlklassifikation von „nicht kreditwürdig“ sind für den Kreditgeber um ein Vielfaches höher als bei einer Fehlklassifikation von „kreditwürdig“, was bei der Analyse berücksichtigt werden muss.
In dem geschilderten Fall kann die Wahl des Algorithmus keinen Beitrag zur Verbesserung des Ergebnisses leisten, solange der Aufbau der Analyse nicht fallbezogen erfolgt. Insofern ist selbst ein hohes Maß an technisch-algorithmischem Wissen hier nicht hilfreich bzw. ausreichend.
Und nicht immer sind die Fälle so offensichtlich. Ohne profundes Domänenwissen im Bereich Ökonomie und Business ist ein Data Scientist somit bereits hier zum Scheitern verurteilt.
Ähnliche Erfahrungen habe ich auch vor kurzer Zeit bei einem Hackathon gemacht. In tiefer Überzeugung haben fast alle Gruppen komplexere Methoden, zumeist Varianten von Neuronalen Netzen, auf das Problem angewendet. Gewonnen hat letztlich die Gruppe, die eine simple Logistische Regression verwendet hat. Sie hatte das Problem richtig verstanden und die Daten entsprechend aufbereitet. Dies deckt sich mit meinen Erkenntnissen aus den verschiedenen Studiengängen. Bei den gleichen Projekten schneiden die Studierenden mit einem ökonomischen Hintergrund nach der Vermittlung des technisch-algorithmischen Wissens zumeist besser ab, als Studierende mit einem Hintergrund aus anderen Disziplinen, die dann zwar im technisch-algorithmischen Bereich besser ausgebildet sind, denen aber nicht das ökonomische Wissen in ausreichendem Maße zur Verfügung steht.
Aus meiner Sicht, hat dies auch Implikationen für die Gestaltung von Data Science Studiengängen in den Bereichen Ökonomie und Business. Eine zu starke Fixierung auf den technisch-algorithmischen Bereich ist aus den oben genannten Gründen nicht zielführend, wenn die Studierenden nicht die notwendige ökonomische Vorbildung haben. Hier muss sich die Ausbildung sehr viel stärker auf die Vermittlung des Domänenwissens konzentrieren, um die Studierenden praxistauglich zu machen.
Es ist aber auch ein Irrglaube anzunehmen, dass es ausreichend ist, neben dem technisch-algorithmischen Bereich einfach isoliert das Domänenwissen zu vermitteln in der Annahme, dass die Verbindung zwischen den beiden Bereichen dann automatisch von den Studierenden hergestellt wird. Dies passiert nach meiner Erfahrung in der Mehrzahl der Fälle nicht. Entsprechend muss die gezielte Verbindung beider Bereiche eine besondere Beachtung im Lehrplan finden. Nach meiner Überzeugung lässt sich dies am besten durch eine Vielzahl an Cases und praktischen Gruppenprojekten realisieren, die sich von Beginn des Studiums an vor allem auch mit dem Setup von Analyseprojekt und Daten befassen, basierend auf ökonomischen Fallbeispielen, die zuvor in den Veranstaltungen diskutiert wurden.
Frankfurt School gGmbH
Adickesallee 32-34
60322 Frankfurt am Main

