

To Author's Page
Currently in the media, one may find numerous articles about the opportunities and future relevance of machine learning and artificial intelligence. Several success stories seem to prove this. As a consequence, universities and business schools are increasingly focusing on these topics; this also includes Frankfurt School of Finance & Management.
Questions, therefore, arise as to why these topics are currently in the spotlight, and whether they are just a hype or sustainable trends. The subject of this blog post is to explain what is new about the developments in these areas and why these developments have led to new potentials.
Machine learning and artificial intelligence are not new, but there has been a great leap forward in recent years. Especially the advances in machine learning are the driving forces for modern data analytics and artificial intelligence. The aim of machine learning is to extract knowledge from data. Thus, it can be applied to nearly everything where data contains relevant information, from predicting customer needs and behaviour to fraud detection, the prediction of capital markets, etc.
Going far beyond the abilities of traditional statistical analysis, modern data analytics reinvents data analysis by consequently utilizing the opportunities of today’s digital technologies. There are many success stories about applying modern analytics; this leads to the question of why modern data analysis is so successful. To answer this, we can identify four main reasons:
When I used econometric analysis for my research at the university in the mid-1980s, I had to type in the data manually from statistical yearbooks and other paper-based sources. Thus, the amount of data for the analysis was limited.
In contrast, nowadays we digitally record vast masses of data. Storage costs have decreased drastically. Every company can store the data which is generated in its systems in detail. Furthermore, it can purchase masses of data from external data providers to enrich their own data.
The data is very granular. Because of the progress in technology, there is no need to preprocess and aggregate the data anymore. In former times, with every aggregation, information loss was accompanied.
Moreover, we do not only record structured data, but we also collect unstructured data, created in social media, for example. Here we have sources for analyzing the attitudes and sentiments of customers for example.
The development of most of the classical statistical methods was influenced by limited calculation power. When Gauß developed the least squares regression method in 1795, only printed calculation tables and simple mechanical calculation tools were available to support calculations. Even I learned statistics at school with a slide rule [1] and later with a pocket calculator. As a consequence, the development of the methods was focused on performing as few calculations as possible resulting in strong assumptions like linearity or normal distribution.
Today, broad processing power is available, which continuously grows. Not only the processors of the computers are getting faster, but also special processing units designed for calculation are available, e. g. for neural networks or bitcoin mining. Furthermore, cloud services with a focus on calculation are available, which gives us the opportunity, to perform more complex calculations.
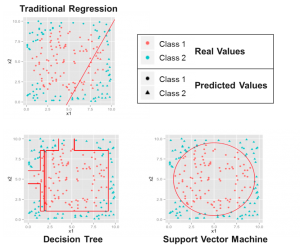
Accordingly, a vast variety of methods and algorithms were developed in the past years, many of them under the term “machine learning”. They are free of restricting assumptions like linearity or specific underlying distributions, and therefore can model the world like it is; nonlinear and dynamic. Figure 1 demonstrates the capabilities of these methods. The colours indicate the real class membership, e. g. creditworthy and not creditworthy or spam and not spam. The symbols, on the other hand, show the class membership estimated by the respective procedure. The greater the match, the better the method in this case.
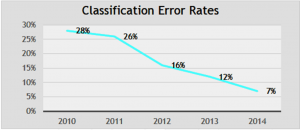
A very promising family of algorithms is summarized under the term “deep learning”. These are specific types of neural networks with specific learning capabilities. Their development caused a jump in the quality of data analytics in many areas. Figure 2 shows an example of the shift in quality when categorizing pictures.
In traditional data analysis, a sample of the reality to be modelled is first generated (see Figure 3). In the next step an algorithm, like the ordinary least squares regression method (OLS), is used to build a model that best approximates this sample data. The quality of the approximation is then validated. If the quality is high, the model is applied to reality, for example, to make forecasts.
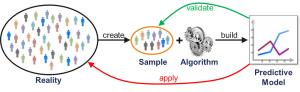
The underlying assumption here is that a high approximation quality will also produce a high forecasting quality. In practice, this is very often not the case. Often the sample is not completely representative, and there are noise and outliers in the data. Usually, the algorithm is not able to distinguish between correct and incorrect data. This is called “overfitting” if the quality of the approximation (also called fitting) is high, but that of the application is poor.
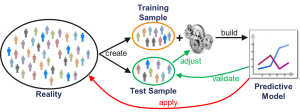
In modern data analytics, the data is split into training and test data (see Figure 4). The training data is then used to build the model, and the test data is used to validate its prediction quality. Furthermore, in many modern algorithms, there exist parameters to adjust the sensitivity (also called complexity) of the algorithm against the data. The purpose is to filter out the irregular data and to concentrate on the underlying regularities. With this, the prediction quality can be maximized via the test data.
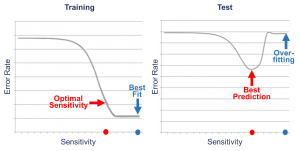
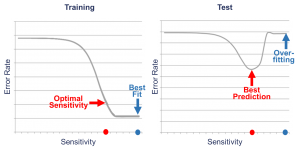
Figure 5 shows an example. In both graphs, the vertical axis represents the error rate and the horizontal axis the sensitivity of the algorithm. The left graph visualizes the approximation qualities for different sensitivities and the right graph the corresponding prediction qualities. The maximal approximation quality can be achieved with
the maximum sensitivity. Here the model fits best to the training data. But if the model is applied to the test data, the result is different. For the test data, the quality increases when the sensitivity increases at first. But in contrast to the approximation quality, the prediction quality deteriorates after reaching a saddle point due to overfitting effects. At this saddle point, the model produces the best forecasts.
The challenge is to find this optimal sensitivity, which cannot be computed directly. Thus, a massive number of calculations is needed to try different sensitivities. The aim is not to fit the model best to the data, but to find the underlying regularities.
Another technique is ensemble learning. Here, multiple models are created using different algorithms. The result is finally the combination of their predictions (see Figure 6). The models act like different experts having diverse domain experience. The purpose is to reduce the weaknesses and to combine the strengths of the algorithms used.
The progress in machine learning has led to a new generation of AI. AI is not a new research discipline. Researchers like Alan Turing and Joseph Weizenbaum studied how machines can mimic human intelligence in the 1950s. They thought about creating general problem solvers. We are still many years away from being able to develop those machines if this will ever be the case.
When we talk about AI today, we usually mean domain-specific applications. The systems do not have general intelligence; they have a specific intelligence for a dedicated purpose, for example, for playing Go or understanding speech.

When I started to work in the area of AI in the early 1990s, we tried to transfer the knowledge of human experts into systems. We used logic-based programming, e.g. in the form of rules and decision trees, to model the knowledge manually (see Figure 7). The challenge was to extract the knowledge from the human experts and to transform it into rule systems.
We built advisory systems, e.g. for financial investments. The limitation was that the systems could never be more intelligent than the implemented knowledge. Furthermore, the systems often suffered from knowledge gaps. As a consequence, the first generation of AI systems was not successful.
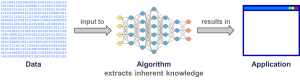
Using machine learning, there is no need to program the knowledge manually anymore. Instead, the algorithms are fed with the data containing the relevant knowledge, and they acquire the inherent knowledge autonomously (see Figure 8). The developed systems, therefore, learn and adapt autonomously instead of simply executing predefined instructions.
The challenge is to provide the algorithms with the data that contains the relevant knowledge. This usually requires large amounts of granular data. Furthermore, the results have to be verified to ensure, that the algorithms identified the regularities and not only spurious correlations.
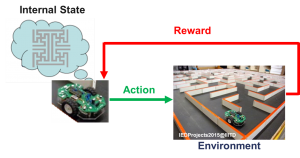
A very promising technique is the so-called “reinforcement learning” which is a kind of smart self-learning. The algorithm trains itself by interacting with its environment. Based on a state, for example, a specific situation in a chess game or a position in a maze, it tries an action and gets a reward for the result (see Figure 9). The better the result, the higher the reward. Thus, it learns by itself via trial and error to perform the best actions. To learn strategies, the learning processes are not one-periodic, but multi-periodic. The higher the calculation capacity, the higher is the number of possible trials.
A very famous example is AlphaGo [6], the Go-playing system from Google. It was able to beat the world champions spontaneously. Go is one of the hardest games in the world for AI because of the huge number of different game scenarios and moves. The number of potential legal board positions is greater than the number of atoms in the universe.
The core of AlphaGo is a deep neural network. It initially learned to play using a database of around 30 million recorded historical moves. After this phase, the system was cloned and it was trained by playing large numbers of games against other instances of itself using reinforcement learning to improve its play. During this training, AlphaGo learned new strategies which were never played by humans.
Another milestone in the development of modern AI is Libratus [7], an AI trained to play poker. In January, Libratus has beaten four of the world’s best poker players in a 20-day tournament in a demoralizing way. Poker is a game with imperfect information, as many markets in the business context. Besides the ability to play poker, Libratus has to act intelligently in other ways. So it is required to bluff and correctly interpret misleading information.
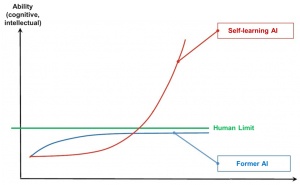
In summary, it can be stated that the potentials of machine learning and artificial intelligence are enormous. The advances enable us to create applications that go beyond our human abilities (see Figure 10).
At present, the part of AI that is most being integrated into consumer and business applications is based on image processing, text processing, and speech processing. The quality of many applications based on these functionalities has reached 99% accuracy due to the successes in machine learning. This is a critical threshold of making these applications acceptable for users and companies.
We are currently at the beginning of the development, and cannot yet foresee the range of possible applications. However, an ethical framework is needed to ensure that the technology is developed and used in the interests of people.
Sources:
[1] http://en.wikipedia.org/wiki/Slide_rule
[2] Sachan, L.: Logistic Regression Vs Decision Trees Vs SVM, http://www.edvancer.in/logistic-regression-vs-decision-trees-vs-svm-part1
[3] Brown, G.: Deep learning for image classification, http://www.nvidia.com/content/events/geoInt2015/LBrown_DL_Image_ClassificationGEOINT.pdf
[4] Roßbach, P.; Karlow, D.: Structural Minimization of Tracking Error, Frankfurt School of Finance & Management [to be published]
[5] Shaikh, F.: Getting ready for AI based gaming agents – Overview of Open Source Reinforcement Learning Platforms, http://www.analyticsvidhya.com/blog/2016/12/getting-ready-for-ai-based-gaming-agents-overview-of-open-source-reinforcement-learning-platforms
[6] Moyer, C.: How Google’s AlphaGo Beat a Go World
Champion, http://www.theatlantic.com/technology/archive/2016/03/the-invisible-opponent/475611
[7] Solon, O.: Poker computer trounces humans in big step for AI, http://www.theguardian.com/technology/2017/jan/30/libratus-poker-artificial-intelligence-professional-human-players-competition
[8] Furrer, F. J.: Rezensionen, in: Informatik Spektrum, Heft 4, 2017, S. 393
Frankfurt School gGmbH
Adickesallee 32-34
60322 Frankfurt am Main


26 November, 2017