
To Author's Page
The current affair about Spectre and Meltdown, which affects many of the processors in use, clearly shows that there is no real security in the IT area. Security is always gradual, and the degree of security is highly dynamic. A high level of security today can drop to a low-level tomorrow if the corresponding critical security hole is discovered. The question is not whether a vulnerability exists – it is a well-known fact that there is no perfect software – but when a vulnerability will be discovered.
But what happens when the “bad guys” discover and exploit the vulnerability first? Particularly, for systems whose security mechanisms are only implemented in the software, there is a danger that they will get into an unforeseen and uncontrolled state and cause considerable damage. Security and cryptography specialist Bruce Schneier states:”If you think technology can solve your security problems, then you don’t understand the problems and you don’t understand the technology.” [Schneier 2000]
However, it is one of the most important features of the blockchain concept that fundamental security mechanisms are implemented via software protocols in order to prevent manipulation and abuse of power. Especially, blockchain applications, which are constructed according to the pure Code-is-Law philosophy, are condemned to security, because in the case of a security relevant event, an effective correction mechanism does not exist. If a system is to function without human control or intervention, it must be ensured that it always fulfills its functions correctly in accordance with its requirements and that it cannot be influenced externally. However, this contradicts the above-mentioned assumption that such a level of security is not possible.
Inspired by this discussion, this article deals with the security of blockchain applications. For this purpose, a 4-layer architecture of a blockchain system (see Figure 1) is developed, and the security aspects are discussed on the basis of these layers.
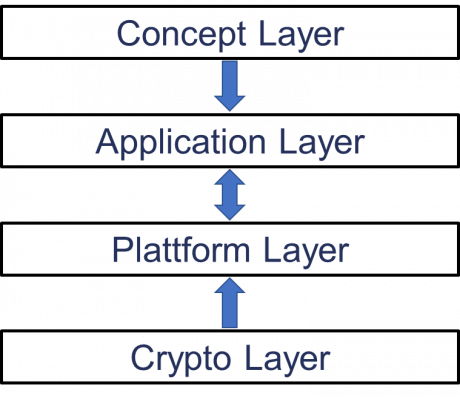
Figure 1: 4-Layer Architecture of a Blockchain System
The aim is to show at which levels security problems can arise, to sharpen the necessary security awareness and to stimulate a discussion about the further development of the blockchain concept. In the following, the term security is not only considered in the narrower sense of attacks on a system, but also in the broader sense, which includes the functionality of the system. This broader concept of security therefore also includes the consequences of errors of different causes, which can lead to the system not functioning as intended. Due to the distribution and popularity of the platform, this contribution refers primarily to Ethereum in the technical parts, which can be considered as the most important representative of the implementation of a blockchain approach in the narrower sense.
One of the constitutive elements of blockchain architecture is cryptography. In most publications on this topic, it is assumed that the cryptographic methods used are (sufficiently) secure. Security in cryptography is based on the fact that no algorithms for solving specific mathematical questions have been found to date [Esslinger 2014], e.g. the discrete logarithm problem. In other words, security in cryptography is based on the insolvability of these mathematical questions. The consequence is that an attacker only has the chance to apply trial and error. By determining the number of possible solutions, e.g. by specifying the key length, the necessary time requirement can be set so high that finding the correct solution with the given technical possibilities is not possible in an acceptable time. Thus, the cryptographic methods are considered safe as long as (a) no algorithms are found to solve the mathematical questions without difficulty or (b) the necessary computing power is not available to find the correct solution in reasonable time.
Blockchain concepts are essentially based on two cryptographic approaches: hash functions and asymmetric cryptography.
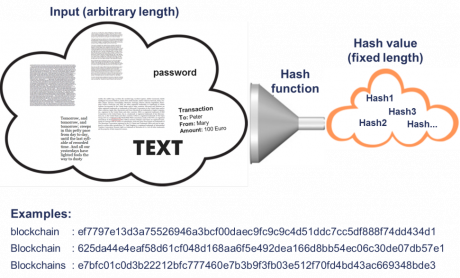
Figure 2: Hash Function
Hash functions map an input of arbitrary length to a sequence of characters with fixed length (see Figure 2). The same input always has the same output (hash value). Hash functions are designed in such a way that similar inputs lead to very different outputs. They are one-way functions, i.e. it is not possible to recalculate from output to input. Since an unlimited number of inputs are mapped to a limited number of outputs, this concept theoretically results in an infinite number of inputs for every possible hash value.
Frankfurt School gGmbH
Adickesallee 32-34
60322 Frankfurt am Main


