
To Author's Page
With the application of data analytics in the fields of economics and business, understanding, selection and preparation of data plays a decisive role to achieve good and valid results. Furthermore, the need for understanding does not start with the data, but already with the underlying case, on the basis of which, for example, the cost function and quality metrics must be determined. Typically, 70-80% of the project time is spent on the data selection and preparation phases, which documents their importance.
Methods and algorithms are then applied to the prepared data to perform the analysis, e.g., to create a forecasting model. A variety of methods is available for this purpose, ranging from simple linear approaches, such as statistical OLS regression, to more complex non-linear approaches, such as random forest, to highly complex approaches, such as deep learning.
Although the more complex approaches have had many success stories in recent times, they are only useful if they are fed with the “right” data. In comparison to that, the choice of the algorithm often only marginally contributes to the result.
Basically, an algorithm can only learn what is provided to it by the data. Thus, the selection of the “right” data for the specific case is of crucial importance. A data scientist must have understood the underlying problem and be able to select the appropriate data and prepare them for the analysis.
Additionally, the information an algorithm needs to create a valid model is often hidden in the data. It is an illusion to assume that the algorithms can find and extract this information autonomously. Instead, so-called feature engineering is required to make the hidden information visible to the algorithms. In some cases, this involves simple processes, such as the transformation of export volumes into export quotas in order to make them comparable between countries. However, some of the processes are more complex, such as finding cyclical information in time-related data.
Regardless of the complexity, however, this requires expert knowledge in the field of economics. For these reasons, domain knowledge or domain expertise is defined as one of the fundamental skills of a data scientist (see also the following figure).
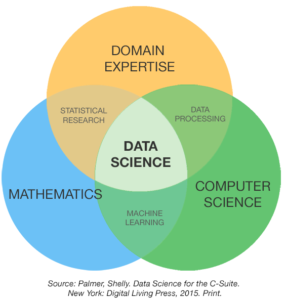
If this knowledge is not sufficiently available, the algorithms are often applied more or less blindly to the available data. The analyst then trusts the standard quality metrics of the software tools used to evaluate the results, without being able to judge whether they are suitable for the case or not. Such analyses can have fatal consequences in practice.
I often make such experiences with students who have no previous economic education and instead have a background in mathematics, physics or computer science. Typical in the case studies they do in the lectures is the above described behavior and the belief in good results based on the algorithms and metrics used. Even when asked, students are often not aware that something is wrong or what is wrong.
A typical case is a credit scoring analysis. In this case, the available data has an imbalanced distribution, since there are significantly more loans in practice where the result was positive. This imbalanced distribution must be taken into account both in the data preparation and in the metrics used, as the algorithm should focus the classification model on identifying the “not creditworthy” class. It is of no use to a bank if it can only reliably identify the “creditworthy” class. However, this is often exactly what the results are, if the appropriate domain knowledge does not exist.
If, for example, the data material consists of 90% of cases with a positive credit history and only 10% of cases with a negative one, an accuracy (fraction of correct predictions) of 90% would be achieved if all positive cases were correctly identified using the model and all negative ones were identified incorrectly. Using the accuracy as quality metric, the algorithm would focus on identifying the larger class, since it has a higher potential optimizing this metric.
There exist different approaches to deal with this imbalance in class distribution. These must be checked in order to select the most appropriate variant. There are combinations of approaches and metrics that do not produce the desired results. A classic case is the artificial creation of a balanced distribution of both classes using up- or downsampling in conjunction with accuracy as a metric. Again, a high accuracy does not mean that the “not creditworthy” class is sufficiently well identified. This can be checked, for example, by examining the so-called Confusion Matrix. In my experience, however, the need for this is often not recognized when domain knowledge is missing.
The credit scoring case is still quite obvious. Nevertheless, these mistakes are made again and again in the case of lack of domain knowledge, even if similar cases have been discussed in the classroom before. The problem is that even the cost function is not understood. The cost of a misclassification of “not creditworthy” is many times higher than the cost of a misclassification of “creditworthy”, which must be taken into account in the analysis.
In such a case, the choice of the algorithm cannot contribute to the improvement of the result as long as the setup of the analysis is not done adequately. In this respect, even a high degree of technical-algorithmic knowledge (mathematics and computer science in relation to the figure above) is not helpful or sufficient here.
The cases are not always so obvious as in the credit scoring case. Without profound domain knowledge in the field of economics and business, the data scientist is therefore already doomed to failure.
I had similar experiences recently at a hackathon. In deep conviction, almost all groups applied complex methods, mostly variants of neural networks, to the problem. In the end, the winner was the group that used simple logistic regression. They had understood the problem correctly and prepared the data accordingly. This is in line with my findings from my various courses in data analytics. Having the same projects as tasks, students with an economic background knowledge usually do better after the teaching of technical-algorithmic knowledge than students with a background from other disciplines who are better educated in the technical-algorithmic areas, but who do not have the economic knowledge available to the same extent.
In my opinion, this has implications for the design of data science programs in the fields of economics and business. For the reasons mentioned above, a too strong fixation on the technical-algorithmic areas is not appropriate if the students do not have an economic background. In this case, the education must focus much more on teaching domain knowledge in order to prepare the students for practice.
However, it is also a misbelief to assume that it is sufficient to simply teach the domain knowledge in isolation, in addition to the technical-algorithmic knowledge, assuming that the connection between these areas is then automatically established by the students. In my experience, this does not happen for the majority of students. Accordingly, the connection between these areas must be given special attention in the curriculum. In my experience, this can best be achieved by a large number of cases and practical group projects, which should be conducted from the very beginning of the study program. These should primarily deal with the correct setup of analysis projects and the selection and preparation of data based on economic or business cases whose basics were discussed before in class.
Frankfurt School gGmbH
Adickesallee 32-34
60322 Frankfurt am Main


